반응형
안녕하세요.
이번엔 랜덤 포레스트입니다.
제 생각에 가장 핵심은 " 1 < N " 인 것 같아요. 하나보다 여러개일때 더 나은 성능을 보인다.
[7-1] 여러 분류기

- 더 좋은 분류기를 만드는 매우 간단한 방법은 각 분류기의 예측을 모아서 가장 많이 선택된 클래스를 예측하는 것 (다수결 투표, 직접 투표 방식)

- 다수결로 예측된 분류기가 가장 뛰어난 개별 분류기보다 정확도가 높은 경우가 많다.
- 각 분류기 : 약한 학습기, 앙상블 : 강한 학습기 (큰 수의 법칙)
- 모든 분류기가 클래스의 확률을 예측할 수 있으면 개별 분류기의 예측을 평균 내어 확률이 가장 높은 클래스를 예측 하는게 가능함 (간접 투표)
- 모든 분류기가 클래스의 확률을 추정할 수 있어야 하므로 SVC도 probability 매개변수를 True로 지정
[7-2] 배깅과 페이스팅
- 배깅 (bootstrap aggregating) : 훈련 세트에서 중복을 허용하여 샘플링 하는 방식
- 페이스팅 : 훈련 세트에서 중복을 허용하지 않고 샘플링 하는 방식
- 배깅이 한 예측기를 위해 같은 훈련 샘플을 여러 번 샘플링하는게 가능함
- 부트스트랩 : 여러 번의 복원 추출을 허용하여 표본을 구성하는 방식 (뽑았다가 다시 넣고 다시 뽑기 반복 하는 거)

- 생성된 예측기가 훈련을 마치면 앙상블은 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 생성
- 분류 : 최빈값, 회귀 : 평균 (앙상블의 결과는 원본 데이터 셋으로 하나의 예측기를 훈련 시킬 때보다 편향은 비슷하나 분산은 줄어듦)

- 결정 트리 하나보다 앙상블의 예측이 더 일반화가 잘된 것 같다
- 부트스트래핑 : 각 예측기가 학습하는 데이터셋에 대한 다양성이 증가하므로 배깅이 페이스팅보다 편향이 조금 더 높음 (다양성 증가) 샘플링 편향
- 다양성 증가 = 상관 관계 감소 이므로 앙상블의 분산을 감소시킴
- 결론 : CPU 되면 배깅이랑 페이스팅 둘 다 해보고 결정
- oob(Out - of - Bag) 평가 (앙상블 모델의 성능 평가)
- 배깅 할 때 한번도 선택되지 않은 샘플을 의미 평균적으로 각 예측기에 훈련 샘플의 63% 정도만 샘플링되고 37%는 oob가 됨
- 앙상블의 평가는 각 예측기의 oob 평가를 평균하여 얻음
- 아마 oob가 한번도 선택되지 않은 샘플이니 test set 데이터 처럼 unseen 데이터라서 성능 평가에 사용됨

[7-3] 랜덤 패치와 랜덤 서브스페이스
- 랜덤 패치 : 이미지와 같은 고차원 데이터 셋을 다룰 때, 훈련 특성과 샘플을 모두 샘플링 하는 방식
- 랜덤 서브스페이스 : 훈련샘플을 모두 사용하고 특성은 샘플링 하는 방식
- 특성 샘플링은 더 다양한 예측기를 만들며 편향을 늘리는 대신 분산을 낮춤
[7-4] 랜덤포레스트
- 랜덤 포레스트는 일반적으로 배깅 (혹은 페이스팅) 방법을 적용한 결정 트리의 앙상블
- max_samples 을 훈련 세트의 크기 지정
- 트리의 노드를 분할 할 때 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성을 주입함
[7-4-1] 엑스트라트리
- 랜덤포레스트에서 트리를 만들때 각 노드는 무작위로 특성의 서브셋을 만들어 분할에 사용함
- 트리를 더욱 무작위하게 만들기 위해서 최적의 임곗값을 찾는 대신 후보 특성을 사용해 무작위로 분할 한 다음 그 중에서 최상의 분할을 선택함
- 익스트림 랜덤 트리 | 엑스트라 트리 : 극단적으로 무작위한 트리
- 모든 노드에서 특성마다 최적의 임계값을 찾는것이 가장 오래걸리는 작업이므로 랜덤포레스트보다 엑스트라 트리가 빠름
[7-4-2] 특성 중요도
- 랜덤 포레스트의 장점 : 특성의 상대적 중요도를 측정하기 쉬움
- 사이킷런 : 어떤 특성을 사용한 노드가 평균적으로 불순도를 얼마나 감소시키는지 확인하여 특성의 중요도를 측정함
- 사이킷런에서 특성마다 자동으로 점수(불순도를 얼마나 감소시키는지)를 계산하고 정규화 함
[7-5] 부스팅 : 에이다부스트, 그래디언트 부스팅
- 부스팅 : 약한 학습기 여러개를 연결하여 강한 학습기를 만드는 앙상블 방법
- 부스팅 아이디어 : 앞의 모델을 보완하며 일련의 예측기를 학습시키는것
[에이다부스트]
- 틀린거 집중 학습 : 틀린 부분에 가중치 부여해서 더 강한 학습기로 만듦
- 가중치 3개 : 변수에 대한 가중치, 각 학습기에 대한 가중치, 데이터에 대한 가중치
- 각 학습기의 예측값 : 변수에 대한 가중치 사용
- 최종 예측값 : 각 학습기에 대한 가중치 사용
- 에러율 계산 및 모델 훈련 : 데이터에 대한 가중치 사용
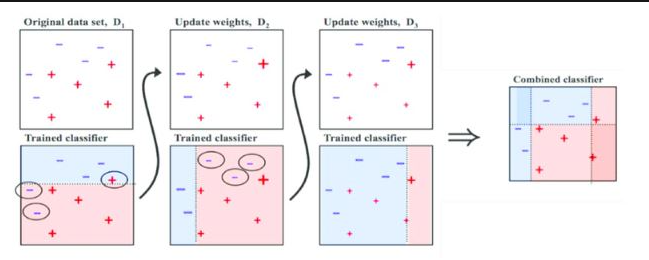
- 잘못 분류된 샘플의 가중치는 절반 정도만 높아짐
- 경사 하강법과 비슷한 면모 : 비용 함수를 최소화하기 위해 예측기의 모델 파라미터를 조정하는 것 처럼 에이다 부스트도 좀 더 좋은 모델을 만들기 위해서 앙상블에 예측기를 추가함
- 모든 예측기가 훈련을 마치면 이 앙상블은 배깅이나 페이스팅과 비슷한 방식으로 예측을 만듭니다. : 모든 약한 학습기가 훈련을 마친 후에 각 학습기의 예측을 어떤 방식으로든 조합하여 최종 예측을 만드는것 → 배깅방식에서는 단순 투표를 사용해서 최종 예측값을 산출했지만, adaboost 에서는 각 학습기의 가중치를 사용하여 최종 예측값을 만듦
- 각 샘플 가중치 w(i)는 초기에 1/m으로 초기화 됨 : 모두 동일한 가중치를 가지고 시작함을 의미
- 첫번째 예측기가 학습되고 가중치가 적용된 에러율 r1이 훈련 세트에 대해 계산됨 : 첫번째 예측기가 얼마나 정확하게 예측하는지 측정하기 위해서 에러율 r1을 계산함

m = 전체 데이터 수
i = i 번째 데이터
w(i) = i번째 샘플에 대한 가중치
- error(i)는 i번째 데이터에 대한 예측이 틀린 경우 1, 맞은 경우 0
- 틀린 경우 가중치를 좀 더 높게 조정됨
- 예측기의 가중치는

- 에타 : 학습률
- 예측기가 정확할수록 가중치가 더 높아지게 됨
- 음수 값도 나올 수 있음
- 최종 예측 : 모든 예측기의 예측을 계산하고 예측기 가중치를 더해서 예측 결과를 만듦
- 예시
- 첫 번째 약한 학습기 (Weak Learner 1):
- 가중치: w1=0.3
- w1=0.3
- 예측: Prediction1={−1,1,−1,1,−1} (5개의 데이터 포인트에 대한 예측)
- Prediction1={−1,1,−1,1,−1}
- 두 번째 약한 학습기 (Weak Learner 2):
- 가중치: w2=0.4
- w2=0.4
- 예측: Prediction2={1,1,−1,−1,1}
- Prediction2={1,1,−1,−1,1}
- 세 번째 약한 학습기 (Weak Learner 3):
- 가중치: w3=0.3
- w3=0.3
- 예측: Prediction3={−1,−1,1,1,−1}
- Prediction3={−1,−1,1,1,−1}
- 첫 번째 데이터 포인트의 최종 예측값:(최종 예측값이 음수이므로, 이 데이터 포인트는 -1 클래스로 분류)
- Final Prediction for Data Point 1=0.3×(−1)+0.4×1+0.3×(−1)=−0.3+0.4−0.3=−0.2
- 두 번째 데이터 포인트의 최종 예측값:(최종 예측값이 양수이므로, 이 데이터 포인트는 1 클래스로 분류)
- Final Prediction for Data Point 2=0.3×1+0.4×1+0.3×(−1)=0.3+0.4−0.3=0.4
- 첫 번째 약한 학습기 (Weak Learner 1):
[Adaboost]
- adaboost 를 정리해보면, 초기 학습기에서 제대로 예측하지 못한 부분에 가중치를 부여하여 더 강한 학습기를 만드는 알고리즘이며, 각 학습기에서 예측하기 위해서 변수에 대한 가중치와 데이터를 사용하여 예측값을 만들고, 만들어진 예측값과 데이터 포인트의 가중치를 사용해서 약한 부분을 강화한 후, 앙상블 과정에서 최종 예측값을 만들때는 예측기 자체의 가중치를 사용하는것
- 예측기 생성 → 분류 → 에러율 계산 → 예측기의 가중치 계산 → 데이터 포인트에 대한 가중치 업데이트 → 두번째 예측기 생성 → 반복 후 앙상블
[7-5-2] 그래디언트 부스팅
- 참고 페이지 : 머신러닝 - 15. 그레디언트 부스트(Gradient Boost) (tistory.com)
- 그래디언트 부스팅 학습 방식
- residual 예측하기 : residual이 더이상 작아지지 않을때까지 반복
- 그래디언트 부스팅 방식은 하나의 leaf 부터 시작하는데 이 leaf는 타겟 값에 대한 평균임
 3개의 변수를 가지고 몸무게가 아닌 residual 을 예측하자.
3개의 변수를 가지고 몸무게가 아닌 residual 을 예측하자.- [키, 좋아하는색상, 성별을 기반으로 몸무게 예측하는 모델]
- single leaf의 타겟 추정 값은 (88 + 76 + 56 +…) / 6 = 71.2 이므로, single leaf로 몸무게를 예측하면 모두 다 71.2로 예측함
- 여기서 그럼 실제 값과의 차이를 보자


- 이런 식으로 우리가 모델을 만들었을 때 마지막 리프 노드에 residual 값이 두개 인데 그럴 땐 평균 넣으면 됨
머신러닝 - 15. 그레디언트 부스트(Gradient Boost)
앙상블 방법론에는 부스팅과 배깅이 있습니다. (머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)) 배깅의 대표적인 모델은 랜덤 포레스트가 있고, 부스팅의 대표적인 모
bkshin.tistory.com
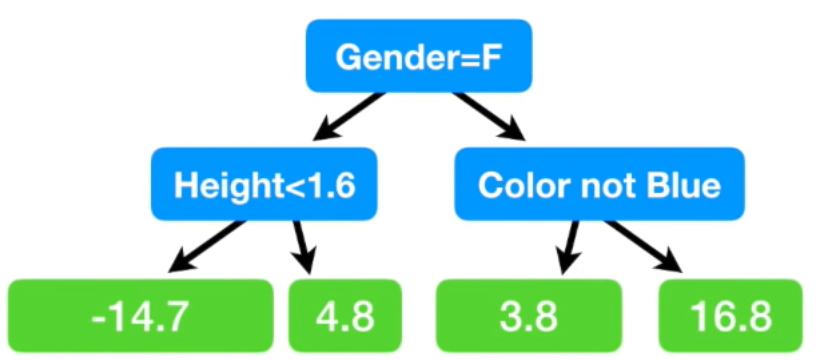
평균 넣으면 이렇게 됨 여기서 초기 트리를 조합해보자 ~
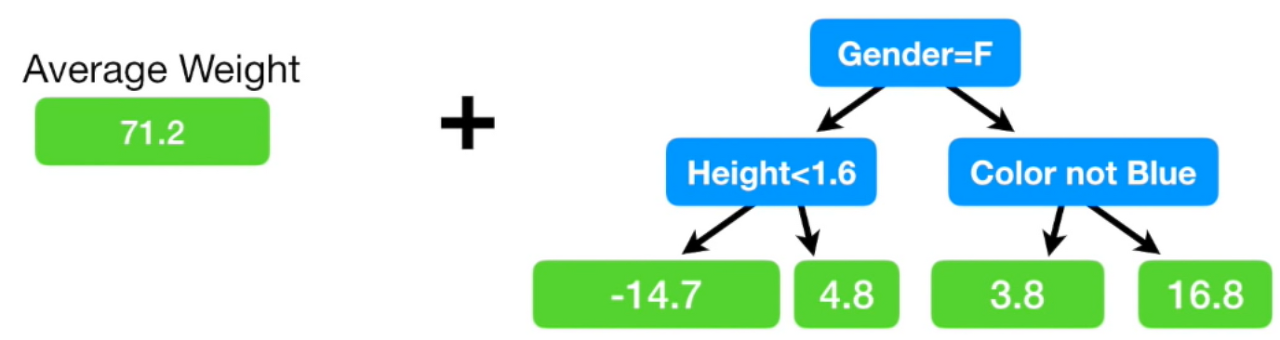
여기서 보면 성별이 남성이고, 좋아하는 색이 파랑이면 residual을 16.8로 예측했는데 이게 무슨 말이냐면 71.2 + 16.8 을 하면 88이 나오는데 성별이 남자고 좋아하는 색이 파랑이면 88로 예측한 것

- 우리가 만든 모델이 예측한 몸무게와 실제 몸무게가 88로 일치함 좋은것 같지만 과적합을 가진…. 모델…
- 이를 해결하기 위해서 조절 하는 게 학습률(0~1) 인데 이는 residual을 예측하는 모델에 학습률을 곱함으로써 과적합 해결 가능

- 학습률을 0.1로 설정하고 했을 때 모델이 예측한 몸무게는 72.9로, 첫 single leaf 모델이 예측한 71.2 보다는 실제 값에 더 가까워졌음
- 에이다 부스트와 비슷한 방법이지만 반복마다 샘플의 가중치를 수정하는게 아니라 이전 예측기의 잔여 오차에 새로운 학습기를 학습시킴
- 첫번째 모델 → 잔여오차 → 잔여오차에 대해 2번째 모델 훈련 → 2번째모델의 잔여오차 → 3번째 모델 훈련 …
- 최종 예측 : 모든 트리의 예측 더하기
- 앙상블 만들기
- 위의 방식으로 그래디언트 부스팅 방식이 진행된다.
 최적의 트리수 : 조기종료기법 사용하기
최적의 트리수 : 조기종료기법 사용하기- learning_rate 매개변수가 각 트리의 기여도를 조절함 낮게 설정하면 트리개수가 많아짐 (축소라고 부르는 규제방법)
- 예측기가 너무 많거나 너무 적은 경우

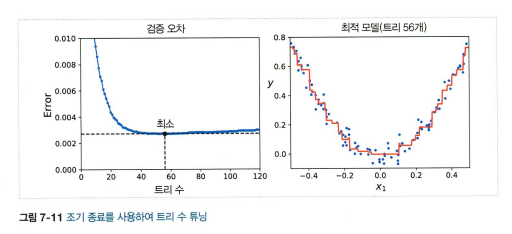
- 확률적 그래디언트 부스팅 (stochastic gradient boosting) : 각 트리 훈련시 훈련 샘플의 비율을 지정하여 각 트리를 학습함. 편향이 높아지는 대신 분산이 낮아지고 훈련 속도가 올라감
- XGBoost
[7-6] 스태킹 (Stacked generalizaion)
- 앙상블에 속한 모든 예측기의 예측을 취합하는 간단한 함수 (직접투표) 말고 취합하는 모델 훈련시키기.
- 예측기는 각각의 샘플에 대해 예측하고 마지막 예측기 (블렌더 | 메타 학습기)가 이 예측을 입력으로 받아 최종 예측을 만듦
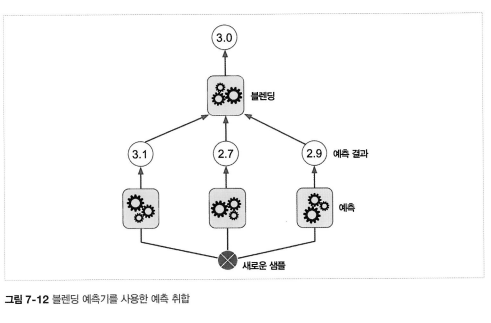
- 블렌더 학습 방법 : 홀드 아웃 (데이터셋 두개로 나누기 train : test)
- 블렌더 여러개 훈련도 가능 !
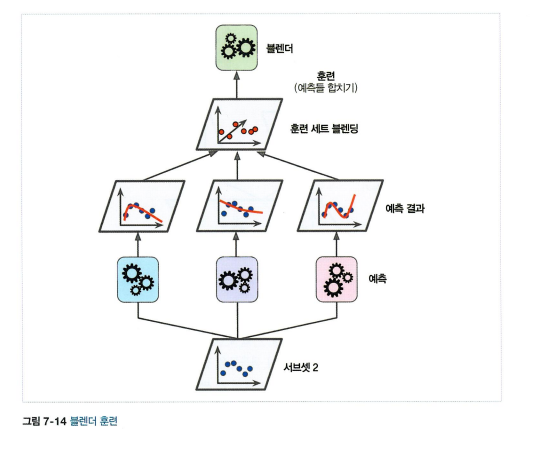
ex) 하나는 선형회귀, 하나는 랜덤포레스트 회귀 …
- 그렇지만 sklearn은 스태킹을 직접 지원하지 않음
반응형
'머신러닝' 카테고리의 다른 글
| [결정트리] 내가 이해한 결정트리 (0) | 2024.05.21 |
|---|---|
| [PCA] 내가 이해한 PCA (0) | 2024.05.21 |
| [정규화] 내가 이해한 릿지, 라쏘, 일라스틱넷 (0) | 2024.05.15 |



댓글